안녕하세요, 지난 시간에는 numpy모듈을 사용하여 편리하게 배열을 만들어 보고 배열 내 요소들을 변경해보았습니다. 오늘은 이어서 numpy를 사용하여 추가적으로 할 수 있는 것을 정리해보겠습니다.
지난 시간처럼 numpy로 만든 배열에 덧셈, 곱셈, 나눗셈 등을 할 수도 있지만 논리식을 이용하여 True/False를 판별할 수도 있습니다. 또한 numpy모듈의 where함수를 사용한다면 True/False로 구성된 array에서 True인 요소들의 인덱스만 추출할 수도 있습니다.
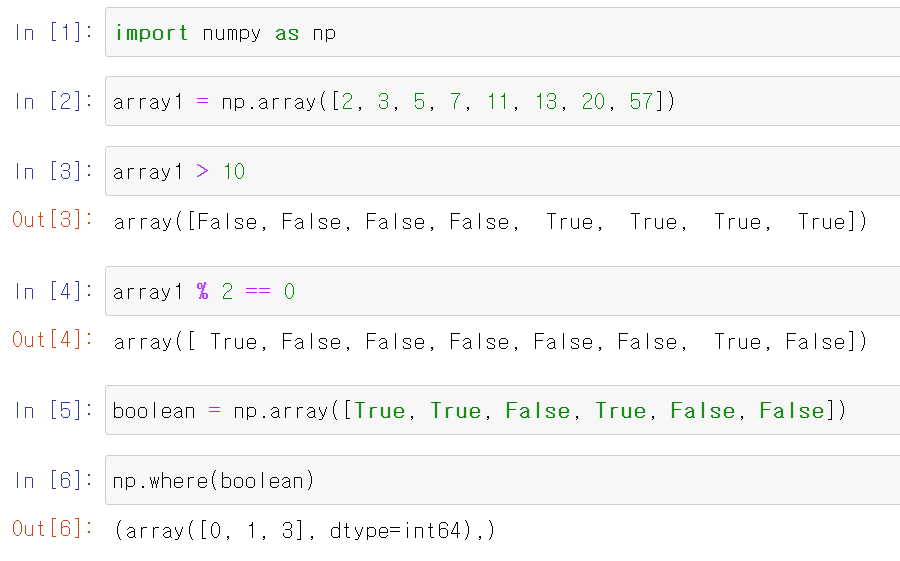
위의 예시를 보시면 array1에 논리식(대소 관계나 나머지 등)을 줌으로써 요소가 논리식을 만족하는지 확인이 가능합니다. 또한 5번에서 True/False로 이루어진 Array에 Where함수를 사용함으로써 True의 인덱스들만 뽑아올 수도 있습니다!
위 내용들을 합쳐서 응용한다면 데이터를 얻었을 때, 내가 원하는 조건을 만족하는 값들만 filtering할 수 있습니다.

filter에 조건을 만족하는 요소들의 인덱스를 넣고 array1[filter]를 이용해 해당 인덱스의 값들을 불러올 수 있습니다.
◆ Numpy 기본 통계
import numpy as np
array1 = np.array([14, 6, 13, 21, 23, 31, 9, 5])
print(array1.max()) # 최댓값
print(array1.min()) # 최솟값
print(array1.mean()) # 평균값
print(np.median(array1)) # 중앙값 : median은 numpy의 함수이므로 이렇게 사용
print(array1.std()) # 표준 편차
print(array1.var()) # 분산
Numpy는 Python으로 데이터 분석을할 때 효율적이고 성능이 좋은 모듈입니다. 한 예로 파이썬의 리스트 내부의 요소들에 곱하기를 해준다고 한다면 반복문을 돌려야 하는데요, 그렇게 되면 몇 초씩 시간이 걸린다고 가정하겠습니다. 이것을 numpy를 이용하면 지난 시간처럼 단 한 줄로 끝낼 수 있고 시간도 더 짧게 소요가 됩니다.(실제 소요 시간은 작동하는 컴퓨터에 따라서도 상이하므로 정확한 수치는 없습니다)
이러한 성능차이는 값들이 저장되는 형태때문인데요, Python에서 리스트에는 여러 자료형을 섞어서 넣을 수 있습니다.(ex. [1, 5, True, 'World', 'a'])
반면 Numpy의 array에는 같은 자료형만 들어갈 수 있습니다. 따라서 속도가 개선이 됩니다.
(ex. [17, 2, 4, 5] , ['Hello', 'World', 'python']
값을 추가하거나 제거하는 작업을 할 때는 Python의 리스트를 사용하는 것이 효율적이나, 수치 계산이 많고 복잡할 때나 행렬 같은 다차원 배열의 경우에는 Numpy의 Array를 사용하는 것이 효율적입니다!
'Python > Data Science' 카테고리의 다른 글
| Python - Pandas (2) (0) | 2021.07.21 |
|---|---|
| Python - Pandas (1) (0) | 2021.07.19 |
| Python - Numpy (2) (0) | 2021.07.16 |
| Python - Numpy (1) (0) | 2021.07.15 |
| Jupyter Notebook(2) (0) | 2021.07.14 |




댓글