안녕하세요, 이제까지 다뤘던 Data Frame들은 나름 작은 수의 Index와 Row들로 구성되어 있었습니다. 이제 많은 수의 Index 및 Row를 갖는 Data Frame들을 어떻게 다룰지 살펴보겠습니다.
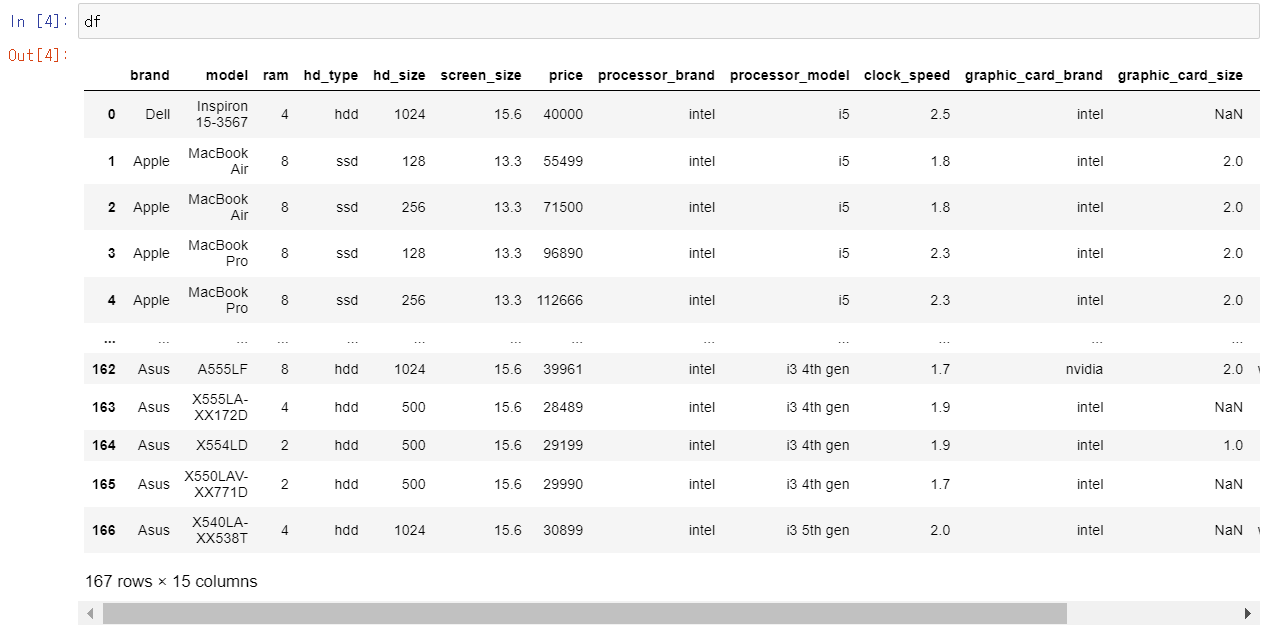
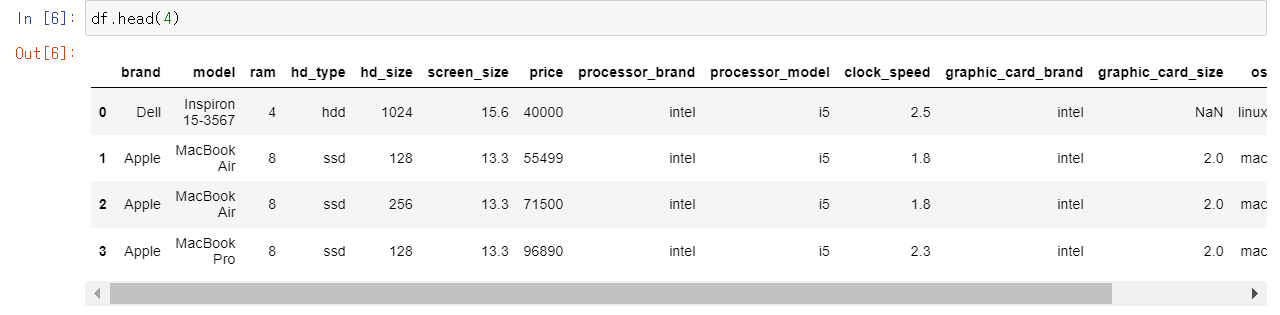
아래 표는 167개의 Index들과 15개의 Column으로 이루어진 Data Frame인데요 Jupyter notebook에서 출력 시 Index가 너무 많아 중간에 ...으로 생략이 된 것을 확인할 수 있습니다. 우선 첫 번째로 위에서부터 원하는 수만큼의 index를 출력하는 방법은 head함수를 사용하는 것입니다. 반대로 아래에서 원하는 수만큼의 index를 출력하려면 head의 반대인 tail함수를 사용해주면 됩니다!

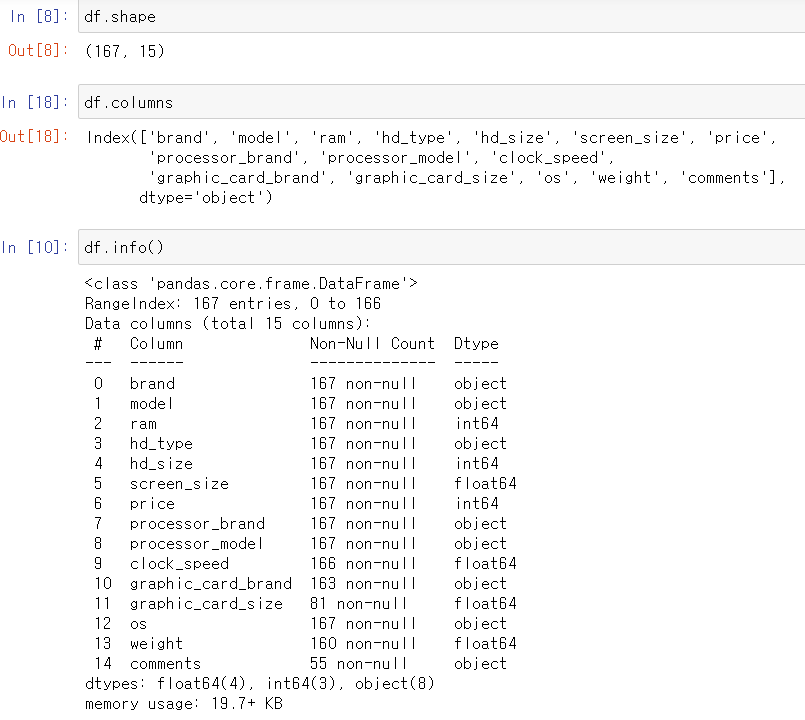
어떠한 Data Frame을 받았을 때 해당 Data Frame의 모양과 각 Columns들에 대해 분석해야 할 때도 있을 텐데요, 이럴 때는 shape, columns, info() 함수를 사용해주면 됩니다! 여기서 주의할 점은 shape과 columns는 함수가 아니므로 ()를 붙이면 안 됩니다! shape는 Data Frame의 Index와 Column의 수를 나타내 줍니다. columns는 Data Frame의 column들을 모두 출력해주고, info()는 columns를 더 자세하게 나타내 주는데요, 각 Column 별로 몇 개의 값을 가지고 있고 Data type이 무엇인지까지 출력해줍니다!
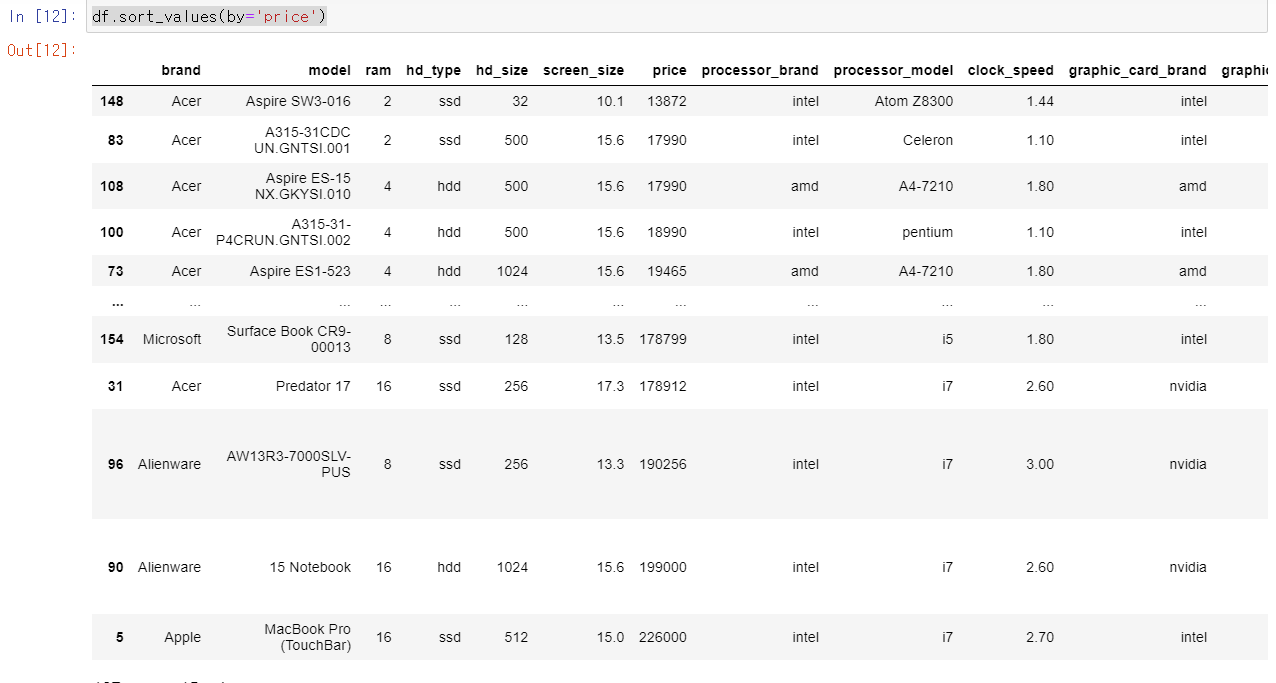
마지막으로 Data Frame을 정렬하는 법을 살펴보겠습니다. sort_values()라는 함수를 사용하면 되는데요, by를 이용해 정렬하고자 하는 기준이 되는 column을 정해주면 됩니다. 기본값은 오름차순으로 정렬이 되는데요, 만약 내림차순으로 정렬하고자 한다면 ascending=False를 넣어주면 됩니다! 여기서 짚고 넘어갈 부분은 이렇게 정렬을 해준다고 원래의 Data Frame 자체가 변경이 되는 것은 아닌데요, 원래의 Data Frame도 정렬이 적용되게 하려면 이전 시간에 배운 inplace=True를 넣어줘야 합니다!

+) 데이터 사이언스에서 중요한 통계를 간단히 보는 함수도 있습니다! describe() 함수를 이용하면 각 Column별로 개수, mean, 산포 등등 많은 것을 한 번에 확인할 수 있습니다!

이렇게 대규모 Data Frame을 조작하는 법에 대해 정리하였는데요, 다음에는 Data Frame의 Series를 다루는 법에 대해 정리해보겠습니다.
'Python > Data Science' 카테고리의 다른 글
| Python - Data Frame 다루기 간단 정리 (0) | 2021.08.16 |
|---|---|
| Python - Series 다루기 (0) | 2021.08.10 |
| Python - Data Frame Index/Column 수정하기 (0) | 2021.08.01 |
| Python - Data Frame 값 추가/삭제 (0) | 2021.07.30 |
| Python - Data Frame 데이터 변경하기 (0) | 2021.07.29 |



댓글