안녕하세요, 지난 시간에 이어 DataFrame에서 인덱 싱하는 것을 정리해보겠습니다. 간략히 지난 시간에 한 것을 정리하고 시작하겠습니다.
-. DataFrame의 요소를 불러오는 것 : df.loc[Row, Column]
-. DataFrame의 하나의 인덱스(Row)를 불러오는 것 : df.loc[Row]
-. DataFrame의 하나의 Column을 불러오는 것 : df[Column]
-. DataFrame의 여러 인덱스(Row)를 불러오는 것 : df.loc[[Row, Row]]
-. DataFrame의 여러 Column을 불러오는 것 : df[[Column, Column]]
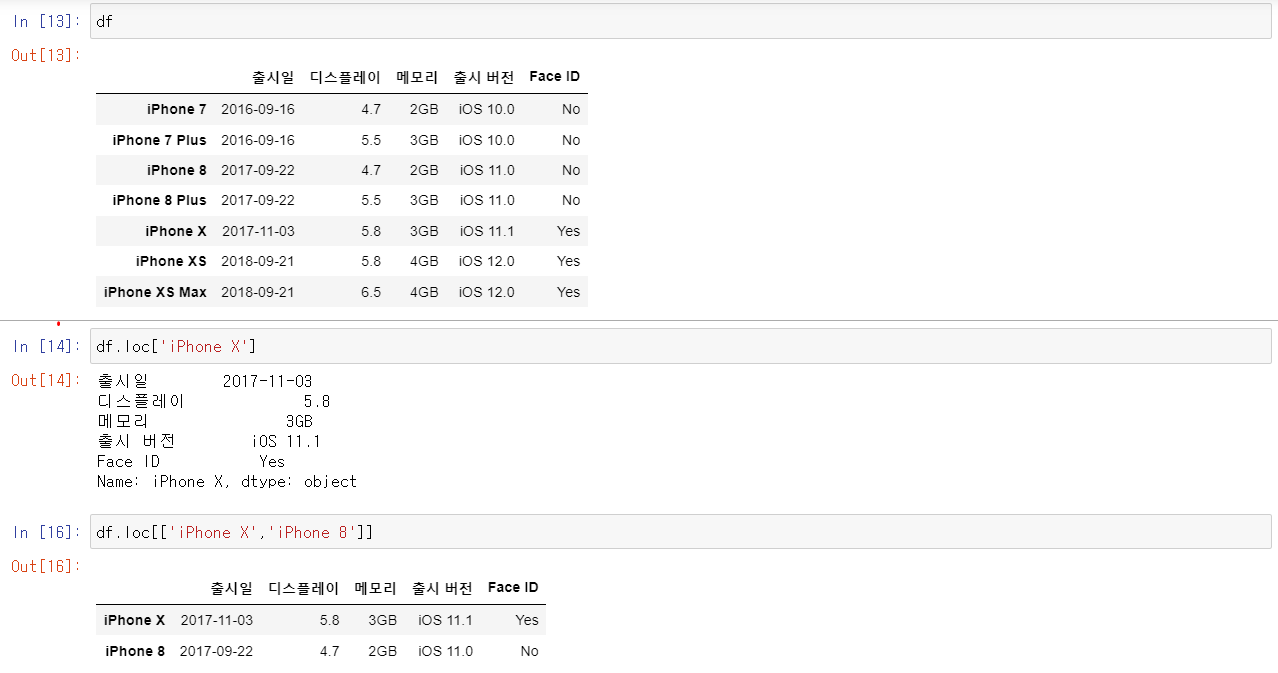
여기서 한 가지 짚고 넘어가자면 위의 예시에서 하나의 인덱스를 뽑을 때와 여러 인덱스를 뽑는 것은 데이터 타입이 다릅니다! 아래를 보면 알 수 있듯 하나의 인덱스를 뽑는 것은 Series 형식이고 여러 개를 뽑는 것은 DataFrame입니다.

Column을 뽑는 것도 형식만 다를 뿐 리스트를 호출하여 여러 개를 호출할 수 있으며 형식 또한 하나일 경우 Series, 여러 개의 경우 DataFrame입니다.

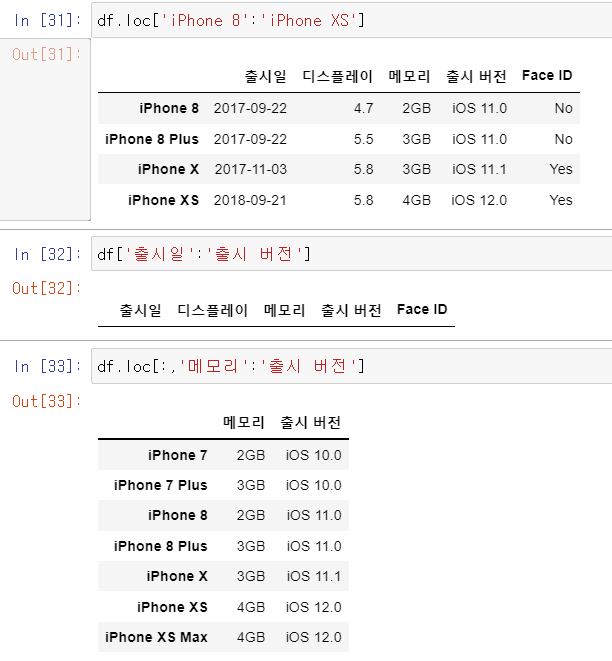
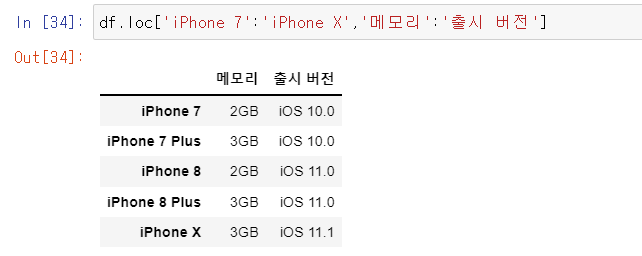
DataFrame에서 Python의 슬라이싱과 동일하게 슬라이싱도 가능합니다. 인덱스(Row)를 슬라이싱 하는 것은 단순하게 리스트의 슬라이싱과 동일하게 할 수 있으나, Column을 인덱싱하는 것은 loc함수를 사용해 줘야 하며 Row에 전체를 의미하는 : 를 붙여줘야 합니다. 아래 정리와 예제를 참고 부탁드립니다.
-. DataFrame의 인덱스(Row)를 슬라이싱하는 것 : df.loc[Row:Row]
-. DataFrame의 Column을 슬라이싱하는 것 : df.loc[:, Column:Column]
-. DataFrame의 인덱스와 Column을 슬라이싱하는 것 : df.loc[Row:Row, Column:Column]
'Python > Data Science' 카테고리의 다른 글
| DataFrame indexing (4) (0) | 2021.07.28 |
|---|---|
| DataFrame indexing (3) (0) | 2021.07.27 |
| DataFrame indexing (1) (0) | 2021.07.24 |
| Python - Pandas (3) (0) | 2021.07.22 |
| Python - Pandas (2) (0) | 2021.07.21 |




댓글